원문 : https://webbylab.com/blog/redux-on-backend/
How We Used Redux on Backend and Got Offline-First Mobile App as a Result | Webbylab
we want to share our experience of building offline-first React-Native application, using Redux-like approach on our NodeJS backend server
webbylab.com
서문
원문 저자는 React Native 앱을 개발하며 NodeJS 백엔드에서 Redux를 사용한 경험을 공유한다.
저자는 kafka나 activieMQ와 같은 도구 없이 event-sourcing architecture를 도입하기 위해 Redux를 사용했다고 한다.
코어 개념을 이해하면 아키텍처의 큰 변화 없이 프로젝트에서 흔히 사용하는 Redux 만으로도 이벤트 소싱의 장점을 누릴 수 있다.
구현 대상 애플리케이션
저자가 구현한 애플리케이션은 3가지 부분으로 구성된 시스템이다.
- 웹 클라이언트 (React + Redux)
- 백엔드 (NodeJS + MongoDB + Redux)
- 네이티브 앱(RN + Redux)
앱의 요구사항은 다음과 같다.
- 모바일 오프라인 모드
- 유저는 오프라인 상태에서 모든 작업을 수행할 수 있으며, 작업 결과는 앱에 저장된다.
- 모바일 앱과 웹 앱은 다를 수 있다.
- 웹에서는 사용자 그룹 통계를 표시하고 모바일에서는 개인의 정보만 표시할 수 있다.
- 요구 사항은 끊임없이 진화한다.
- 즉, 언제든지 상사가 이전 요구사항을 뒤엎고 새로운 피처를 추가할 수 있다.
- 감사 추적(Audit trail) 지원
- 프로젝트는 법적 활동 분야와 밀접하게 연결되어 있다.
데이터에 대해 생각하기
- OS 연산의 결과는 메모리 변환이다.
- 응용 프로그램의 메모리는 일반적으로 상태로 표현한다.
- 상태는 복잡한 DB, 일반적인 파일 또는 일반 자바스크립트 객체로 표현할 수 있다.
- 즉, 애플리케이션의 모든 연산 결과는 상태 변환이다.
- 상태를 어떻게 표현하는가 보다 상태를 어떻게 바꾸느냐가 더 중요하다.
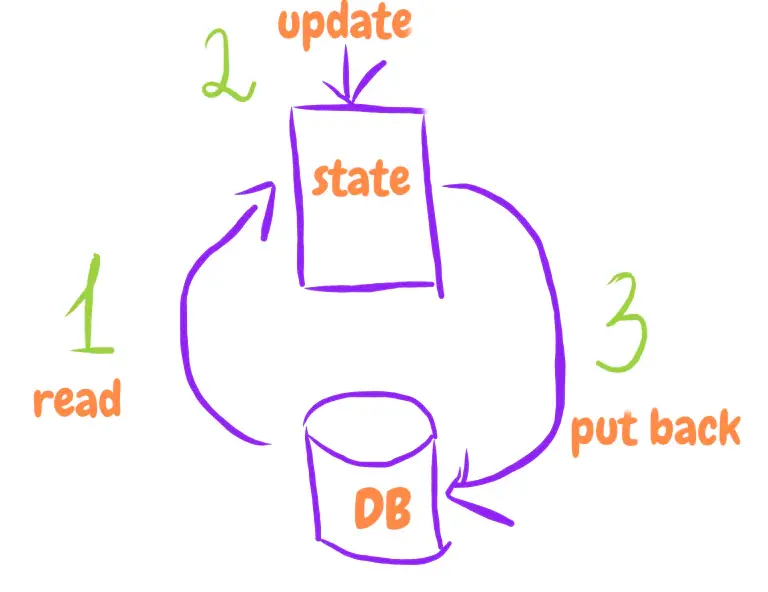
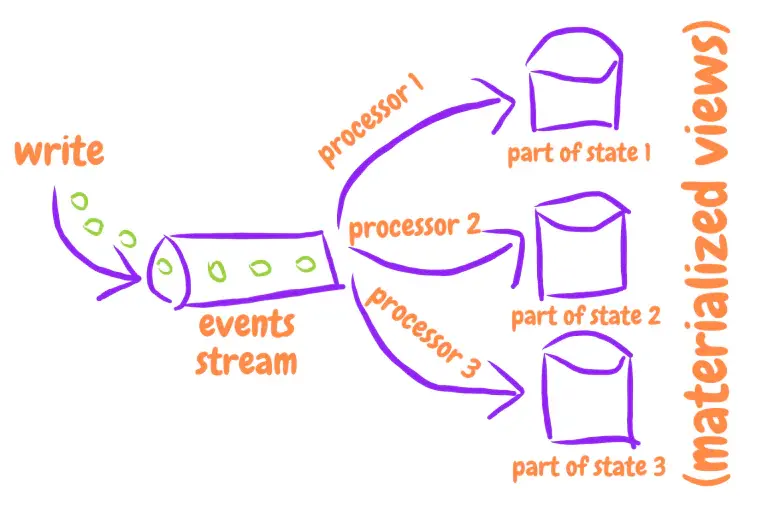
왜 이렇게 해야 할까?
하지만, 우리가 병원에 갈 때를 생각해보자.
병원에는 EMR(진료 차트)라는게 있다.
해당 기록에는 환자의 진료 기록이 들어있다.
따라서 의사는 항상 해당 기록을 통해 우리의 질병의 현재 상태를 유추할 수 있다.
또한 기록을 통해 현재 상테에 어떻게 도달하게 되었나가 분명 중요한 진단 기준이 될 수도 있다.
또한 이전 기록을 통해 현재 상태가 정상인지 아닌지도 쉽게 유추가 가능하다.
즉, 히스토리가 중요한 비즈니스일 경우 이벤트 소싱은 꽤나 도움이 될 것이다.
이벤트 자체가 기록의 대상이 될 것이기 때문이다.
이벤트 소싱을 사용하지 말아야 할 때
동시 업데이트의 위험이 없고 실시간 업데이트의 요구사항이 없는 경우 이벤트 소싱은 일만 늘린다.
리덕스와 이벤트 소싱
- 상태는 앱의 단일 진실 원천이다.
- 뷰는 해당 상태의 표현이다.
- 상태를 변경하려면 뷰 혹은 어딘가에서 이벤트(액션)을 디스패치(전송)해야 한다.
- 리듀서는 이벤트 핸들러다.
- 리듀서는 액션의 배열을 이전 상태에 적용해 모든 액션이 적용된 이후의 상태로 축소(reduce)한다.
- 리듀서는 상태 변경 방법의 단일 진실 원천이다.
이벤트가 리듀서에서 배치 처리되는 모양은 이벤트 소싱과 매우 유사하다.
Redux와 이벤트 소싱은 트랜잭션 상태를 관리하는 동일한 목적을 수행한다.
Redux는 액션(이벤트)에 대한 리듀서가 애플리케이션 상태 변경 방법(how) 대한 단일 진실 원천이 될 수 있음을 보여준다.
Redux의 단일 진실 원천은 store(& reducer)지만, event sourcing 에서 단일 진실 원천은 이벤트라는 것이 다르다.
즉, 같은 이벤트여도 다른 리듀서를 사용한다면 다른 상태가 된다.
두 개념의 공통점을 파악하면 다음과 같다.
- 상태는 이벤트에서 기원한다.
- 이벤트는 변경할 수 없다. (불변)
이벤트는 불변이라는 것이 매우 중요하다.
연산 도중 예측 불가능한 이벤트의 변경이 발생하면, 입력만으로 출력을 투명하게 예측할 수 없다.
즉 상태는 결정적이어야 한다.

구현
다음은 애플리케이션에 어떤 상황이 있는지에 대한 개요다.
사용자는 오프라인 모드에서 시험에 통과할 수 있다.
이 경우 두 가지 요구사항이 존재한다.
- 모바일에서 통과 결과를 기반으로 사용자 정보를 다시 집계한다. (오프라인이건 아니건)
- 어떻게든 백엔드의 DB에서 동일한 사용자 정보를 얻어, 애플리케이션과 완전히 분리된 웹 파트에 표시할 수 있다. (온라인)
/* We rely on thunk-middleware to deal with asyncronous actions.
If you are not familiar with the concept, go check it out,
it may help you to undestand our action creator's structure better */
export function createQuestionAnswerEvent(payload) {
return (dispatch) => {
const formattedEvent = {
type: ActionTypes.ANSWER_QUESTION,
// It's crucial to have timestamp on every event
timestamp: new Date().toISOString(),
payload
};
// Dispatch the event itself, so our regular reducers that are responsible for analytics can process it and recalculate the statistics
dispatch(formattedEvent);
// Dispatch the action that declares that we want to save this particular event
dispatch({ type: ActionTypes.SAVE_EVENT, payload: formattedEvent });
// At some point in time we gonna send all saved events to the backend, but let's get to it later
dispatch(postEventsIfLimitReached());
};
}const initialState = [];
export default (state = initialState, action) => {
switch (action.type) {
// Append event to our events log
case ActionTypes.SAVE_EVENT:
return state.concat(action.payload);
// After sending events to the backend we can clear them
case ActionTypes.POST_EVENTS_SUCCESS:
return [];
/* If user wants to clear the client cache and make sure
that all analytics is backend based, he can press a button,
which will fire CLEAR_STORAGE action */
case ActionTypes.CLEAR_STORAGE:
return [];
default:
return state;
}
};export function postEventsIfLimitReached() {
return async (dispatch, getState) => {
const events = getState().events;
/* If user is online perform batch events submission */
if (events.length > config.EVENTS_LIMIT && getState().connection.isConnected) {
try {
await api.events.post(events);
dispatch({ type: ActionTypes.POST_EVENTS_SUCCESS });
} catch (e) {
dispatch({ type: ActionTypes.POST_EVENTS_FAIL });
}
}
};
}백엔드 구현
백엔드의 NodeJs 앱에는 이벤트 묶음을 수신하고 MongoDB에 저장하는 POST 경로가 있다.
다음은 몽고디비 스키마다 (몽구스 사용)
const EventSchema = new Schema({
employeeId : { type: 'ObjectId', required: true },
type : {
type : String,
required : true,
enum : [
'TRAINING_HEARTBEAT',
'ANSWER_QUESTION',
'START_DISCUSSION',
'MARK_TOPIC_AS_READ',
'MARK_COMMENT_AS_READ',
'LEAVE_COMMENT',
'START_READING_MODE',
'FINISH_READING_MODE',
'START_QUIZ_MODE',
'FINISH_QUIZ_MODE',
'OPEN_TRAINING',
'CLOSE_APP'
]
},
timestamp : { type: Date, required: true },
isProcessed : { type: Boolean, required: true, default: false },
payload : { type: Object, default: {} }
});이제 DB에 모든 이벤트가 있으며 이 이벤트를 어떤 방식으로건 간에 처리해야 한다.
이를 위해 애플리케이션의 시작 파일에서 임포트하여 사용하는 클래스를 만든다.
import EventsHandler from './lib/EventsHandler';
const eventsHandler = new EventsHandler();
eventsHandler.start();export default class EventsHandler {
// Initialize an interval
start() {
this.planNewRound();
}
stop() {
clearTimeout(this.timeout);
}
// 주기적으로 이벤트를 배치 처리한다
planNewRound() {
this.timeout = setTimeout(async () => {
await this.main();
this.planNewRound();
}, config.eventsProcessingInterval);
}
async main() {
const events = await this.fetchEvents();
await this.processEvents(events);
}
async processEvents(events) {
const metrics = await this.fetchMetricsForEvents(events);
/* Here we should process events somehow.
But HOW???
We'll get back to it later
*/
/* It's critical to mark events as read after processing,
so we don't fetch and apply the same events every time */
await Promise.all(events.map(this.markEventAsProcessed));
}
async markEventAsProcessed(event) {
event.set({ isProcessed: true });
return event.save();
}
async fetchMetricsForEvents(events) {
/* I removed a lot of domain-related code from this method, for the sake
of simplicity. What we are doing here is accumulating ids of Metrics related to every event from argument events.
That's how we got metricsIds */
return Metric.find({ _id: { $in: metricsIds } });
}
async fetchEvents() {
return Event.find({ isProcessed: false }).limit(config.eventsFetchingLimit);
}
}
이벤트 처리에만 집중할 수 있도록 많은 로직을 제거하였다.
이 클래스로 수행하는 핵심 작업은 다음과 같다.
- 처리되지 않은 이벤트를 DB에서 전부 불러온다.
- 처리에 필요한 이벤트 데이터와 관련된 모든 항목을 불러온다.
- 개인(Session Metric) 및 그룹(Training Metric) 통계를 나타내는 대부분의 Metrics 도큐먼트다
- 어떤 방식으로 이벤트를 처리하고 메트릭을 변경한다. (processEvent 의 주석 영역)
- 변경된 데이터를 저장한다.
- 이벤트를 처리 완료 상태로 표시한다.
보다 강력한 솔루션을 원하는 경우 다음 사항을 고려한다.
- 주기적 배치 처리는 특정 시점에는 일부 이벤트를 전달하였어도, 아직 처리되지 않았을 수 있음을 의미한다.
- MongoDB대신 카프카 사용도 가능하다.
- 이벤트 간 우선순위 지정이 필요할 수도 있다.
- 이벤트는 표준 Mongo의 ObjectId를 사용하지만, 단순히 증분 식별자를 사용하는 것도 괜찮다.
- 무슨 일이 일어나고 있는지, 이벤트의 올바른 순서가 무엇인지 더 쉽게 파악할 수 있다.
이제 이벤트 처리 방법에 대해 알아보자.
이벤트 처리의 어려움
이제 이벤트의 구조는 준비되었다.
하지만 이제 가장 복잡한 질문인 이벤트 처리 방법이 남아있다.

코드 재사용이 해법이다
리덕스의 리듀서를 재사용하면 어떨까?
처음에는 이상하게 들릴 수 있다.
Redux는 클라이언트에서나 쓰는 것이기 떄문이다.
Reducer는 액션과 초기 상태를 파라미터로 받아 새로운 상태를 반환하는 순수 함수다.
프론트엔드 개발자를 위해서는 보통 Redux의 스토어가 Reducer의 호출을 대신해 준다는 점이 특별할 뿐이다.
이 Reducer를 직접 가져다 쓰면 Redux가 없어도 된다.
하지만 아래 두 가지 사항을 명심한다.
- 리듀서에는 부작용이 없어야 한다.
- 부작용은 별도로 보관한다.
- 상태와 이벤트는 불변이다.
1. 먼저 events 배열의 각 이벤트의 관심 대상인 metric을 id를 이용해 어디선가 가져온다.
2. 각 metric에 모든 이벤트를 reducer를 이용해 적용한다.
- 해당 이벤트 중 해당 metric에 영향을 미치는 이벤트만 상태를 변경할 것이다.
- 이벤트는 순서대로 줄세워져 있고, 여러 동일한 타입의 이벤트가 여러번 같은 metric에 영향을 미칠 수 있다.
async processEvents(events) {
const metrics = await this.fetchMetricsForEvents(events);
await Promise.all(metrics.map(async (metric) => {
/* sessionMetricReducer and trainingMetricReducer are just functions that are imported from a separate repository,
and are reused on the client */
const reducer = metric.type === 'SESSION_METRIC' ? sessionMetricReducer : trainingMetricReducer;
try {
/* Beatiful, huh? :)
Just a line which reduces hundreds or thousands of events
to a one aggregate Metric (say analytical report)
*/
const newPayload = events.reduce(reducer, metric.payload);
/* If an event should not reflect the metric in any ways
we just return an initial state in our reducers, so we can
have this convenient comparison by link here */
if (newPayload !== metric.payload) {
metric.set({ payload: newPayload });
return metric.save();
}
} catch (e) {
console.error('Error during events reducing', e);
}
return Promise.resolve();
}));
await Promise.all(events.map(this.markEventAsProcessed));
}- sessionMetricReducer는 개별 사용자의 통계를 계산하는 함수다.
- trainingMetricReducer는 그룹 통계를 계산하는 함수다.
둘다 순수함수다.
우리는 그 둘 함수를 별도의 레포지토리에 저장한 뒤 머리부터 발끝까지 단위 테스트를 적용한다.
뿐만 아니라 해당 리듀서를 클라이언트에서도 사용한다.
핵심은 const newPayload = events.reduce(reducer, metric.payload) 부분이다.
metric.payload는 초기 상태를 의미한다.
초기 상태에 events 배열의 event를 적용한다.
즉, 앱의 데이터를 redux의 state처럼 모델링 할 수 있으면, event 배열을 이용해 직접 reducer를 호출하는 것이 가능하다.

for (const event of events) {
try {
// Pay attention to the params order.
// This way we should first pass the state and after that the event itself
const newPayload = reducer(metric.payload, event);
if (newPayload !== metric.payload) {
metric.set({ payload: newPayload });
await metric.save();
}
} catch (e) {
console.error('Error during events reducing', e);
}
}리듀서 구현 구경하기
import moment from 'moment';
/* All are pure function, that responsible for a separate parts
of Metric indicators (say separate branches of state) */
import { spentTimeReducer, calculateTimeToFinish } from './shared';
import {
questionsPassingRatesReducer,
calculateAdoptionLevel,
adoptionBurndownReducer,
visitsReducer
} from './session';
const initialState = {
timestampOfLastAppliedEvent : '',
requiredTimeToFinish : 0,
adoptionLevel : 0,
adoptionBurndown : [],
visits : [],
spentTime : [],
questionsPassingRates : []
};
export default function sessionMetricReducer(state = initialState, event) {
const currentEventDate = moment(event.timestamp);
const lastAppliedEventDate = moment(state.timestampOfLastAppliedEvent);
// Pay attention here, we'll discuss this line below
if (currentEventDate.isBefore(lastAppliedEventDate)) return state;
switch (event.type) {
case 'ANSWER_QUESTION': {
const questionsPassingRates = questionsPassingRatesReducer(
state.questionsPassingRates,
event
);
const adoptionLevel = calculateAdoptionLevel(questionsPassingRates);
const adoptionBurndown = adoptionBurndownReducer(state.adoptionBurndown, event, adoptionLevel);
const requiredTimeToFinish = calculateTimeToFinish(state.spentTime, adoptionLevel);
return {
...state,
adoptionLevel,
adoptionBurndown,
requiredTimeToFinish,
questionsPassingRates,
timestampOfLastAppliedEvent : event.timestamp
};
}
case 'TRAINING_HEARTBEAT': {
const spentTime = spentTimeReducer(state.spentTime, event);
return {
...state,
spentTime,
timestampOfLastAppliedEvent : event.timestamp
};
}
case 'OPEN_TRAINING': {
const visits = visitsReducer(state.visits, event);
return {
...state,
visits,
timestampOfLastAppliedEvent : event.timestamp
};
}
default: {
return state;
}
}
}- 함수 시작 부분에서 다음 이벤트가 적용되었을 때, 이전 이벤트가 적용되지 않도록 한다.
- 이벤트를 불변의 단일 진실 원천으로 사용하기 위해, 추가 정보가 필요하면 상태를 이용한다.
최종 개요
공통 리듀서를 별도의 레포지토리에 보관하고 서버와 클라이언트에서 재사용한다.
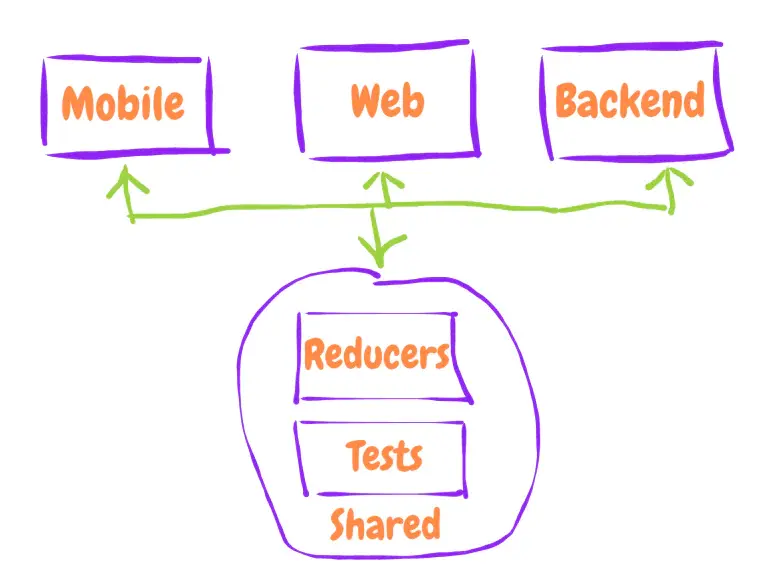
이를 통해 얻은 효과는 다음과 같다.
- 모바일 오프라인 모드
- 웹과 모바일 분석 정보 동기화
- 리듀서는 유지보수 및 확장이 쉽다.
- 테스트와 개발은 한곳에서만 하면 된다.
- 계산에서 버그를 발견해도 이벤트를 이용해 처음부터 다시 계산할 수 있다.
- 타임 트레블링
- 비즈니스 요구 사항이 변경될 때마다 새로운 메트릭을 쉽게 만들고 계산할 수 있다.
- 이벤트 처리가 사용자의 주요 앱 작업 흐름과 독립적으로 백그라운드에서 실행될 수 있으므로 애플리케이션의 성능과 응답성을 크게 향상시킬 수 있다.
- 모든 이벤트를 활용 가능하다는 것은, 시스템을 테스트하고 디버그하는 데 크게 도움이 된다.
- 언제든지 이벤트를 쉽게 재생하고 시스템이 어떻게 반응하는지 관찰할 수 있다.
- 분석 정보 계산에 대한 더 많은 제어권.
- 모바일에서는 실시간 개별 통계
- 웹에서는 통합 집계
- 이벤트는 사용자 활동 분석의 매우 좋은 원천이다. 유용한 비즈니스 정보를 많이 얻을 수 있다.
- 즉시 사용 가능한 완전한 로그(히스토리) 및 감사 추적(audit trail)
사실 이러한 접근 방식은 스트림을 선호한다.
스트림은 애플리케이션의 데이터를 흐름으로 생각하는 방식이다.
이벤트의 무한한 대기열에 애플리케이션이 어떻게 반응하는가를 생각한다. (기존의 요청, 응답 모델과 다르게)
- 클라이언트에서 데이터 변경 사항을 구독하고 (ex 웹소켓),
- 백엔드에서 데이터가 변경될 때마다 클라이언트에 특정 타입의 메세지를 보내는 것이다.
결론
부록 : 오프라인 모드의 문제 해결하기
문제 1. 클라이언트가 백엔드에서 계산된 최신 메트릭을 사용하도록 강제하는 방법은 무엇인가요?
문제 2. 오프라인에서 엔터티를 만들고 해당 ID를 추가로 사용해야 합니다.
문제 3. RN에서 데이터 영속을 위해 무엇을 사용하나요?
import { createStore, applyMiddleware, combineReducers, compose } from 'redux';
import thunkMiddleware from 'redux-thunk';
import * as asyncInitialState from 'redux-async-initial-state';
import { setAutoPersistingOfState, getPersistedState } from '../utils/offlineWorkUtils';
import rootReducer from '../reducers';
const reducer = asyncInitialState.outerReducer(combineReducers({
...rootReducer,
asyncInitialState: asyncInitialState.innerReducer
}));
const store = createStore(
reducer,
compose(applyMiddleware(thunkMiddleware, asyncInitialState.middleware(getPersistedState)))
);
setTimeout(() => {
setAutoPersistingOfState(store);
}, config.stateRehydrationTime);
export default store;offlineWorkUtils의 모듈은 다음과 같다.
export function getPersistedState() {
return new Promise(async (resolve) => {
// A wrapping function around AsyncStorage.getItem()
const encodedState = await getFromAsyncStorage(config.persistedStateKey);
if (!encodedState) resolve(undefined);
// A wrapping function around CryptoJS.AES.decrypt()
const decodedState = decryptAesData(encodedState);
resolve(decodedState);
});
}
export async function setAutoPersistingOfState(store) {
setInterval(async () => {
const state = store.getState();
if (!state || !Object.keys(state).length) return;
try {
// A wrapping function around CryptoJS.AES.encrypt()
const encryptedStateInfo = encryptDataWithAes(state).toString();
// A wrapping function around AsyncStorage.setItem()
await saveToAsyncStorage(config.persistedStateKey, encryptedStateInfo);
} catch (e) {
console.error('Error during state encryption', e);
}
}, config.statePersistingDebounceTime);
}'FrontEnd' 카테고리의 다른 글
| [번역] React TDD 기초 (0) | 2023.03.21 |
|---|---|
| [React] Context API를 활용한 전략 패턴 (0) | 2023.03.19 |
| [Redux] 리덕스의 state, action, reducer (0) | 2023.03.14 |
| 리액트 디자인 패턴 : uncontrolled component pattern (0) | 2023.03.13 |
| [번역] Headless UI Component란 무엇인가? (2) | 2023.03.13 |



