2023.01.23 - [프론트엔드 아키텍처] - 멀티쓰레드 Javascript 1편 : SharedArrayBuffer
멀티쓰레드 Javascript 1편 : SharedArrayBuffer
javascript의 공유 메모리(shared memory)에 대해 알아보고, SharedArrayBuffer와 TypedArray에 대해 알아봅니다. 브라우저에는 세 종류의 멀티쓰레딩 방법이 있습니다. web worker shared werker service worker node.js에는
itchallenger.tistory.com
2023.01.24 - [프론트엔드 아키텍처] - 멀티쓰레드 Javascript 2편 : Atomics 객체와 원자성, 직렬화
Javascript의 공유 메모리 : Atomics와 원자성, 직렬화에 대해 알아보자
이전글 : 2023.01.23 - [프론트엔드 아키텍처] - Javascript의 공유 메모리 : SharedArrayBuffer에 대해 알아보자. Javascript의 공유 메모리 : SharedArrayBuffer에 대해 알아보자. javascript의 공유 메모리(shared memory)에
itchallenger.tistory.com
SharedArrayBuffer 개체를 사용하여 별도의 스레드에서 공유 데이터 컬렉션을 직접 읽고 쓸 수 있습니다,
하지만 잘못하면 한 스레드가 다른 스레드가 작성한 데이터를 망가뜨릴 수 있습니다
Atomics 객체 덕택에 데이터가 손상되는 것을 방지하는 방식으로 해당 데이터로 매우 기본적인 작업을 수행할 수 있습니다.
조정을 위한 Atomic 메서드
# Firefox v88
Uncaught TypeError: invalid array type for the operation
# Chrome v90 / Node.js v16
Uncaught TypeError: [object Int8Array] is not an int32 or BigInt64 typed array.Atomics.wait()
status = Atomics.wait(typedArray, index, value, timeout = Infinity)| not-equal |
제공된 value가 버퍼에 있는 값과 같지 않습니다.
|
| timed-out |
다른 스레드가 할당된 제한 시간 내에 Atomics.notify()를 호출하지 않았습니다.
|
| ok |
다른 스레드가 적시에 Atomics.notify()를 호출했습니다.
|
# Firefox
Uncaught TypeError: waiting is not allowed on this thread
# Chrome v90
Uncaught TypeError: Atomics.wait cannot be called in this contextAtomics.notify()
awaken = Atomics.notify(typedArray, index, count = Infinity)Atomics.notify()는 원래 Linux futex와 같은 Atomics.wake()였지만,
"wake"와 "wait" 메서드와 혼동을 방지하기 위해 이름이 변경되었습니다.
Atomics.waitAsync()
promise = Atomics.waitAsync(typedArray, index, value, timeout = Infinity)타이밍과 비결정론적(Timing and Nondeterminism)
비결정론적 예제
Example 5-1. ch5-notify-order/index.html
<html>
<head>
<title>Shared Memory for Coordination</title>
<script src="main.js"></script>
</head>
</html>Example 5-2. ch5-notify-order/main.js
if (!crossOriginIsolated) throw new Error('Cannot use SharedArrayBuffer');
const buffer = new SharedArrayBuffer(4);
const view = new Int32Array(buffer);
for (let i = 0; i < 4; i++) { // 1
const worker = new Worker('worker.js');
worker.postMessage({buffer, name: i});
}
setTimeout(() => {
Atomics.notify(view, 0, 3); // 2
}, 500); // 3
- 4명의 전용 작업자 스레드가 인스턴스화됩니다.
- 공유 버퍼의 인덱스 0에 락 걸린 쓰레드를 깨웁니다.
- 알림은 0.5초 후에 전송됩니다.
Example 5-3. ch5-notify-order/worker.js
self.onmessage = ({data: {buffer, name}}) => {
const view = new Int32Array(buffer);
console.log(`Worker ${name} started`);
const result = Atomics.wait(view, 0, 0, 1000); // 1
console.log(`Worker ${name} awoken with ${result}`);
};이러한 파일 생성이 완료되면 터미널로 전환하고 다른 웹 서버를 실행하여 콘텐츠를 봅니다.
| Worker 1 started | worker.js:4:11 |
| Worker 0 started | worker.js:4:11 |
| Worker 3 started | worker.js:4:11 |
| Worker 2 started | worker.js:4:11 |
| Worker 0 awoken with ok | worker.js:7:11 |
| Worker 3 awoken with ok | worker.js:7:11 |
| Worker 1 awoken with ok | worker.js:7:11 |
| Worker 2 awoken with timed-out | worker.js:7:11 |
스레드 준비 감지
스레드가 초기 설정을 완료하여 작업을 시작할 준비가 된 시점을 응용 프로그램이 어떻게 결정적으로 알 수 있을까요?
if (!crossOriginIsolated) throw new Error('Cannot use SharedArrayBuffer');
const buffer = new SharedArrayBuffer(4);
const view = new Int32Array(buffer);
const now = Date.now();
let count = 4;
for (let i = 0; i < 4; i++) { // 1
const worker = new Worker('worker.js');
worker.postMessage({buffer, name: i}); // 2
worker.onmessage = () => {
console.log(`Ready; id=${i}, count=${--count}, time=${Date.now() - now}ms`);
if (count === 0) { // 3
Atomics.notify(view, 0);
}
};
}- 4개의 워커를 초기화 합니다.
- 워커에 즉시 메세지를 보냅니다.
- 4명의 작업자 모두의 0번째 항목에 알립니다.
Example 5-5. ch5-notify-when-ready/worker.js
self.onmessage = ({data: {buffer, name}}) => {
postMessage('ready'); // 1
const view = new Int32Array(buffer);
console.log(`Worker ${name} started`);
const result = Atomics.wait(view, 0, 0); // 2
console.log(`Worker ${name} awoken with ${result}`);
};
- 메시지를 상위 스레드에 다시 포스트하여 준비 상태를 알립니다.
- 0번째 항목에 대한 알림을 기다립니다.
명심해야 할 한 가지는 Atomics.wait()를 호출하면 스레드가 일시 중지된다는 것입니다.
이것은 postMessage()를 이후 호출될 수 없음을 의미합니다.
| Firefox v88 | Chrome v90 |
| T1, 86ms | T0, 21ms |
| T0, 99ms | T1, 24ms |
| T2, 101ms | T2, 26ms |
| T3, 108ms | T3, 29ms |
.
예제 : 콘웨이의 인생 게임(Conway's Game of Life)
- 세포가 살아있는 경우:
- 2~3개의 이웃이 살아 있으면 셀은 살아 있습니다.
- 살아있는 이웃이 0개 또는 1개 있으면 셀은 죽습니다(인구 부족을 죽음의 원인으로 시뮬레이션 합니다.).
- 4개 이상의 이웃이 살아 있으면 셀은 죽습니다(죽음의 원인으로 인구 과잉을 시뮬레이션 합니다).
- 세포가 죽은 경우:
- 정확히 3개의 이웃이 살아 있으면 셀이 살아납니다(이것은 번식을 시뮬레이션 합니다).
- 그 외에는 셀은 죽은 상태입니다.
이웃 셀의 판단 조건은 대각선을 포함하여 현재 셀에서 최대 1단위 떨어져 있는 모든 셀을 의미하며
상태는 현재 반복 이전의 상태를 의미합니다.
이러한 규칙을 다음과 같이 단순화할 수 있습니다.
- 정확히 3개의 이웃이 살아 있다면 새로운 셀 상태는 살아 있는 것입니다(시작 방법에 관계없이).
- 셀이 살아 있고 정확히 2개의 이웃이 살아 있으면 셀은 계속 살아 있습니다.
- 다른 모든 경우에는 새 셀 상태는 죽은 것입니다.
구현을 위해 다음과 같은 가정을 합니다.
- 그리드는 정사각형입니다. 걱정할 차원이 하나 줄어들도록 약간 단순화한 것입니다.
- 그리드의 모서리는 연결되어 있습니다.
- 가장자리에 있을 때 경계 외부의 이웃 셀을 평가해야 할 때 다른 쪽 끝에 있는 셀을 보게 된다는 것을 의미합니다.
싱글 스레드 인생 게임
ch5-game-of-life/gol.js (part 1)
class Grid {
constructor(size, buffer, paint = () => {}) {
const sizeSquared = size * size;
this.buffer = buffer;
this.size = size;
this.cells = new Uint8Array(this.buffer, 0, sizeSquared);
this.nextCells = new Uint8Array(this.buffer, sizeSquared, sizeSquared);
this.paint = paint;
}ch5-game-of-life/gol.js (part 2)
getCell(x, y) {
const size = this.size;
const sizeM1 = size - 1;
x = x < 0 ? sizeM1 : x > sizeM1 ? 0 : x;
y = y < 0 ? sizeM1 : y > sizeM1 ? 0 : y;
return this.cells[size * x + y];
}ch5-game-of-life/gol.js (part 3)
static NEIGHBORS = [ // 1
[-1, -1], [-1, 0], [-1, 1], [0, -1], [0, 1], [1, -1], [1, 0], [1, 1]
];
iterate(minX, minY, maxX, maxY) { // 2
const size = this.size;
for (let x = minX; x < maxX; x++) {
for (let y = minY; y < maxY; y++) {
const cell = this.cells[size * x + y];
let alive = 0;
for (const [i, j] of Grid.NEIGHBORS) {
alive += this.getCell(x + i, y + j);
}
const newCell = alive === 3 || (cell && alive === 2) ? 1 : 0;
this.nextCells[size * x + y] = newCell;
this.paint(newCell, x, y);
}
}
const cells = this.nextCells;
this.nextCells = this.cells;
this.cells = cells;
}
}- 이웃 좌표 집합은 알고리즘에서 8개 방향에서 이웃 셀을 보는 데 사용됩니다.
- 이 배열은 모든 셀에 사용해기 위해 미리 선언해 둡니다
- iterate() 메서드는 최소 X 및 Y 값(포함) 및 최대 X 및 Y 값(제외)의 형태로 작동할 범위를 사용합니다.
- 단일 스레드 예제의 경우 항상 (0, 0, 크기, 크기)이지만 여기에 범위를 지정하면 다중 스레드 구현으로 이동할 때 이러한 X와 Y를 사용하여 분할하기가 더 쉬워집니다.
- 이 X 및 Y 경계를 사용하여 전체 그리드를 작업할 각 스레드의 섹션으로 나눕니다.
이 시점까지의 모든 코드는 다중 스레드 구현과 공유됩니다.
Grid 클래스가 완료되면 이제 Grid 인스턴스를 생성 및 초기화하고 이를 UI에 연결할 수 있습니다.
ch5-game-of-life/gol.js (part 4)
const BLACK = 0xFF000000; // 1
const WHITE = 0xFFFFFFFF;
const SIZE = 1000;
const iterationCounter = document.getElementById('iteration'); // 2
const gridCanvas = document.getElementById('gridcanvas');
gridCanvas.height = SIZE;
gridCanvas.width = SIZE;
const ctx = gridCanvas.getContext('2d');
const data = ctx.createImageData(SIZE, SIZE); // 3
const buf = new Uint32Array(data.data.buffer);
function paint(cell, x, y) { // 4
buf[SIZE * x + y] = cell ? BLACK : WHITE;
}
const grid = new Grid(SIZE, new ArrayBuffer(2 * SIZE * SIZE), paint); // 5
for (let x = 0; x < SIZE; x++) { // 6
for (let y = 0; y < SIZE; y++) {
const cell = Math.random() < 0.5 ? 0 : 1;
grid.cells[SIZE * x + y] = cell;
paint(cell, x, y);
}
}
ctx.putImageData(data, 0, 0); // 7
- 화면에 그릴 흑백 픽셀에 대한 상수를 할당하고 사용 할 그리드의 크기(너비)를 설정합니다.
- HTML의 반복 카운터와 캔버스 요소를 가져옵니다. 캔버스 너비와 높이를 SIZE로 설정하고 작업할 2D 컨텍스트를 가져옵니다.
- ImageData 인스턴스를 사용하여 Uint32Array를 통해 캔버스의 픽셀을 직접 수정합니다.
- 이 paint() 함수는 그리드 초기화와 각 반복에서 ImageData 인스턴스를 지원하는 버퍼를 수정하는 데 사용됩니다. 세포가 살아 있으면 검게 칠합니다. 그렇지 않으면 흰색으로 칠해집니다.
- 이제 그리드 인스턴스를 생성하고 size 인수, 셀과 nextCells를 둘 다 담을 수 있을 만큼 큰 ArrayBuffer 인수, 그리고 paint() 함수를 전달합니다.
- 그리드를 초기화하기 위해 모든 셀을 반복하며 각 셀에 임의의 죽은 또는 살아있는 상태를 할당합니다.
- 동시에 결과를 paint() 함수에 전달하여 이미지가 업데이트되도록 합니다.
- ImageData가 수정될 때마다 캔버스에 다시 추가해야 합니다.
- 위에서 초기화가 완료되었으므로 여기서 수행합니다.
ch5-game-of-life/gol.js (part 5)
let iteration = 0;
function iterate(...args) {
grid.iterate(...args);
ctx.putImageData(data, 0, 0);
iterationCounter.innerHTML = ++iteration;
window.requestAnimationFrame(() => iterate(...args));
}
iterate(0, 0, SIZE, SIZE);초기화가 끝났으니, 각 반복에 대해 셀이 어떻게 변경되는지 업데이트 하는 함수를 작성합니다.
해당 함수 내부 로직은 다음과 같습니다.
각 반복에 대해 셀을 적절하게 수정하는 grid.iterate() 메서드를 호출합니다.
각 셀에 대해 paint() 함수를 호출하므로 이미지 데이터가 이미 설정되어 있으므로
putImageData()를 사용하여 캔버스 컨텍스트에 추가하기만 하면 됩니다.
그런 다음 페이지의 반복 카운터를 업데이트하고 requestAnimationFrame() 콜백에서 다음 iteratnion이 발생하도록 예약합니다.
이제 캔버스를 렌더링하기 위한 HTML이 필요합니다.
다행히도 이것은 매우 짧습니다.
ch5-game-of-life/gol.html
<h3>Iteration: <span id="iteration">0</span></h3>
<canvas id="gridcanvas"></canvas>
<script src="gol.js"></script>
멀티쓰레드 인생게임
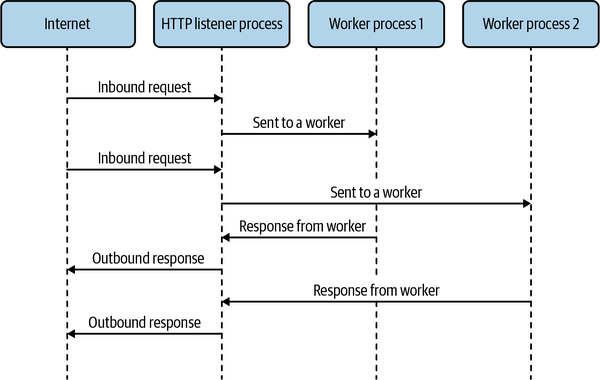
| Purpose | # of Bytes |
| Cells (or next cells) | SIZE * SIZE |
| Cells (or next cells) | SIZE * SIZE |
| Image data | 4 * SIZE * SIZE |
| Worker thread wait | 4 |
| Coordination thread wait | 4 |
이전 예제의 .html 및 .js 파일을 각각 thread-gol.html 및 thread-gol.js라는 새 파일에 복사합니다.
이 새로운 JavaScript 파일을 참조하도록 thread-gol.html을 편집합니다.
ch5-game-of-life/thread-gol.js (part 1)
const BLACK = 0xFF000000;
const WHITE = 0xFFFFFFFF;
const SIZE = 1000;
const THREADS = 5; // must be a divisor of SIZE
const imageOffset = 2 * SIZE * SIZE
const syncOffset = imageOffset + 4 * SIZE * SIZE;
const isMainThread = !!self.window;ch5-game-of-life/thread-gol.js (part 2)
if (isMainThread) {
const gridCanvas = document.getElementById('gridcanvas');
gridCanvas.height = SIZE;
gridCanvas.width = SIZE;
const ctx = gridCanvas.getContext('2d');
const iterationCounter = document.getElementById('iteration');
const sharedMemory = new SharedArrayBuffer( // 1
syncOffset + // data + imageData
THREADS * 4 // synchronization
);
const imageData = new ImageData(SIZE, SIZE);
const cells = new Uint8Array(sharedMemory, 0, imageOffset);
const sharedImageBuf = new Uint32Array(sharedMemory, imageOffset);
const sharedImageBuf8 =
new Uint8ClampedArray(sharedMemory, imageOffset, 4 * SIZE * SIZE);
for (let x = 0; x < SIZE; x++) {
for (let y = 0; y < SIZE; y++) {
// 50% chance of cell being alive
const cell = Math.random() < 0.5 ? 0 : 1;
cells[SIZE * x + y] = cell;
sharedImageBuf[SIZE * x + y] = cell ? BLACK : WHITE;
}
}
imageData.data.set(sharedImageBuf8);
ctx.putImageData(imageData, 0, 0);- SharedArrayBuffer는 syncOffset보다 16바이트 뒤에서 종료됩니다. 4개의 스레드 각각에 대한 동기화에 4바이트가 필요하기 때문입니다.
ch5-game-of-life/thread-gol.js (part 3)
const chunkSize = SIZE / THREADS;
for (let i = 0; i < THREADS; i++) {
const worker = new Worker('thread-gol.js', { name: `gol-worker-${i}` });
worker.postMessage({
range: [0, chunkSize * i, SIZE, chunkSize * (i + 1)],
sharedMemory,
i
});
}
const coordWorker = new Worker('thread-gol.js', { name: 'gol-coordination' });
coordWorker.postMessage({ coord: true, sharedMemory });
let iteration = 0;
coordWorker.addEventListener('message', () => {
imageData.data.set(sharedImageBuf8);
ctx.putImageData(imageData, 0, 0);
iterationCounter.innerHTML = ++iteration;
window.requestAnimationFrame(() => coordWorker.postMessage({}));
});그런 다음 조정 작업자를 추가하고다음 메시지를 통해 조정 작업자임을 알리며 sharedMemory를 전달합니다.
메인 브라우저 스레드는 이 조정 작업자와만 대화합니다.
이 조정 작업자는 SharedMemory에서 이미지 데이터를 가져오고, 적절한 UI를 업데이트하고,
애니메이션 프레임을 요청한 후에만 메시지를 수신할 때마다 메시지를 게시하여 반복하도록 설정합니다.
ch5-game-of-life/thread-gol.js (part 4)
} else {
let sharedMemory;
let sync;
let sharedImageBuf;
let cells;
let nextCells;
self.addEventListener('message', initListener);
function initListener(msg) {
const opts = msg.data;
sharedMemory = opts.sharedMemory;
sync = new Int32Array(sharedMemory, syncOffset);
self.removeEventListener('message', initListener);
if (opts.coord) {
self.addEventListener('message', runCoord);
cells = new Uint8Array(sharedMemory);
nextCells = new Uint8Array(sharedMemory, SIZE * SIZE);
sharedImageBuf = new Uint32Array(sharedMemory, imageOffset);
runCoord();
} else {
runWorker(opts);
}
}계속해서 runWorker()를 정의해 보겠습니다.
ch5-game-of-life/thread-gol.js (part 5)
function runWorker({ range, i }) {
const grid = new Grid(SIZE, sharedMemory);
while (true) {
Atomics.wait(sync, i, 0);
grid.iterate(...range);
Atomics.store(sync, i, 0);
Atomics.notify(sync, i);
}
}그런 다음 무한 루프를 시작합니다. 루프는 다음 작업을 수행합니다.
- 동기화 배열의 i번째 요소에서 Atomics.wait()를 수행합니다.
- 조정 스레드에서 적절한 Atomics.notify()를 수행하여 계속 진행할 수 있습니다.
- 다른 스레드가 준비되어 데이터가 기본 브라우저 스레드로 이동하기 전에 데이터 변경과 셀 및 nextCells에 대한 참조 교환을 시작할 수 있기 때문에 여기에서 조정 스레드를 기다리고 있습니다.
- Grid 인스턴스에서 반복을 수행합니다. 조정 스레드가 전달한 범위(range)에서만 동작하고 있음을 기억합니다.
- 이전 코드를 자세히 보면 y 기준으로 쪼개서 작업하고 있습니다.
- Grid 반복이 완료되면 이 작업을 완료했음을 메인 스레드에 알립니다.
- 조정 스레드에서 Atomics.store()를 사용하여 동기화 배열의 i번째 요소를 1로 설정한 다음 Atomics.notify()를 통해 대기 중인 스레드를 깨워 수행합니다.
- 우리는 0 상태에서 벗어나는 전환을 우리가 어떤 작업을 해야 한다는 표시로 사용하고,
- 0 상태로 다시 전환하여 작업을 완료했음을 알립니다.
이제 초기화 메시지 이후 메인 브라우저 스레드의 메시지를 통해 트리거되는 runCoord() 함수로 코드를 마무리하겠습니다.
ch5-game-of-life/thread-gol.js (part 6)
function runCoord() {
for (let i = 0; i < THREADS; i++) {
Atomics.store(sync, i, 1);
Atomics.notify(sync, i);
}
for (let i = 0; i < THREADS; i++) {
Atomics.wait(sync, i, 1);
}
const oldCells = cells;
cells = nextCells;
nextCells = oldCells;
for (let x = 0; x < SIZE; x++) {
for (let y = 0; y < SIZE; y++) {
sharedImageBuf[SIZE * x + y] = cells[SIZE * x + y] ? BLACK : WHITE;
}
}
self.postMessage({});
}
}지금까지 소스코드를 쪼개어 보아 이해가 더 어려울 수 있습니다.
깃헙의 전체 소스코드와 설명을 대조해가며 읽으면 더 쉽게 이해하실 수 있습니다.
(핵심은 조정 스레드를 이용한 낙관적 락인 것 같습니다.)
Atomics와 이벤트
- 응용 프로그램의 메인 스레드는 Atomics.wait()를 호출하면 안 됩니다.
- 간단한 Node.js 스크립트의 메인 스레드에서 Atomics.wait() 호출을 수행할 수 있지만 더 큰 애플리케이션에서는 그렇게 하지 않는 것이 좋습니다.
예를 들어 기본 Node.js 스레드가 들어오는 HTTP 요청을 처리하거나 운영 체제 신호를 수신하는 핸들러가 있는 경우
Atomics.waiy() 작업이 시작될 때 이벤트 루프가 중지되면 어떻게 될까요?
ch5-node-block/main.js
#!/usr/bin/env node
const http = require('http');
const view = new Int32Array(new SharedArrayBuffer(4));
setInterval(() => Atomics.wait(view, 0, 0, 1900), 2000); // 1
const server = http.createServer((req, res) => {
res.end('Hello World');
});
server.listen(1337, (err, addr) => {
if (err) throw err;
console.log('http://localhost:1337/');
});- 2초마다 앱이 1.9초 동안 일시 중지됩니다.
$ node main.js노드 프로세스가 실행되면 터미널에서 다음 명령을 여러 번 실행하고 각 호출 사이에 임의의 시간을 기다립니다.
$ time curl http://localhost:1337또 다른 질문은 여전히 남아 있습니다.
생성된 각 스레드의 주요 목적이 무엇인지 미리 지정하는 것이 좋습니다.
각 스레드는 Atomics 호출을 많이 사용하는 CPU 사용량이 많은 스레드이거나
Atomics 호출을 최소화하는 이벤트 사용량이 많은 스레드가 됩니다.
- 메인 스레드에서 Atomics.wait()를 사용하지 마세요
- CPU를 많이 사용하는 스레드를 지정하고 Atomics 호출을 많이 사용하고 이벤트가 발생하는 스레드를 지정합니다.
- 간단한 "bridge" 스레드를 사용하여 적절한 경우 메시지를 대기하고 게시하는 것을 고려하십시오.
다음은 응용 프로그램을 디자인할 때 따를 수 있는 매우 높은 수준의 지침입니다.
그러나 때로는 좀 더 구체적인 패턴이 요점을 파악하는 데 도움이 됩니다.
다음번에는 좀 더 구체적인 패턴들을 다루어 봅니다.
'FrontEnd' 카테고리의 다른 글
| 리덕스는 왜 단일 스토어를 사용하는가? (0) | 2023.01.26 |
|---|---|
| Javascript 멀티쓰레딩 : 언제 멀티쓰레딩을 사용해야 할까 (0) | 2023.01.24 |
| 멀티쓰레드 Javascript 2편 : Atomics 객체와 원자성, 직렬화 (0) | 2023.01.24 |
| 멀티쓰레드 Javascript 1편 : SharedArrayBuffer (0) | 2023.01.23 |
| 자바스크립트 스킬 티어 리스트 (0) | 2023.01.22 |


